Object SED
VOSA helps to build a Spectral Energy Distribution (SED) for each object in the file combining user input data with data obtained from VO catalogues, taking into account extinction properties for deredening the observed fluxes and marking photometric points where IR or UV excess is detected.
In the SED section of VOSA you can visualize how the final SED has been built, what points have been considered, where the photometric points come from (VO catalogue, user input, etc), some properties of the data when coming from VO catalogues (including data quality when available) and, finally, where an IR excess has been detected by VOSA.
You can also edit the final SED and make decisions about what points are considered and how they enter the final SED. This is specially tricky when there are different photometric values for the same filter (coming from the user input file and/or VO catalogues).
Point options and actions
There are some options that allow you to decide how the final SED is built:
- Delete: Be careful. If you mark the 'Delete' checkbox for any point and then click the 'Apply Changes' button, this point will be deleted from the SED without confirmation. And you will not be able to undo the operation. So please, be careful.
- Ignore: If you mark the 'Ignore' checkbox for a point, this point will be ignored. It is as if it is deleted but it will be there so that you can recover it later if you want. It will not be part of the final SED, it will not be considered to make averages if there are more points for the same filter, it will not be shown in the SED plots...
- Nofit: Points marked as 'nofit' will be considered for the final SED but they will not be used in the model fits (chi-square or bayes). The point will be shown in plots in a different color.
- Uplim: Points marked as 'uplim' are assumed to be upper limits, not actual photometric values. But remember that VOSA does not really consider upper limits in the fits. These points will be authomatically marked as 'nofit' too. They will be shown in plots in a different color and they won't be used for the fits.
- Bad: Points marked as 'bad' are assumed to be points with bad quality for whatever reason. They will be marked as 'nofit' too. In some cases VOSA authomatically marks a VO photometry point as 'bad' when we know how to detect 'bad quality' in that particular VO catalogue.
Several values for the same filter
In some cases it happens that there are several observed photometric values for the same filter. For instance, if you have given a value for one filter in your input file and another value is found, for the same filter, in a VO catalogue.
When this happens, VOSA will calculate an average of the different values and this average is the value that goes to the final SED.
The average is calculated as:
$$ \overline{F}=\frac {\sum ( {\rm F}_{\rm i}/\Delta{\rm F}_{\rm i} )}{\sum ( {1}/\Delta{\rm F}_{\rm i} )}$$
$$\Delta\overline{F} = \sqrt{\sum \Delta{\rm F}_{\rm i}^2}$$
if the observed error for any of the involved fluxes is zero, the value of the error that will be used in this calculation will be
$$\Delta{\rm F}_{\rm i} = 1.1 \ {\rm F}_{\rm i} \ {\rm Max}(\Delta{\rm F}/{\rm F})$$
(so that it is the biggest relative error, that is, the smallest weight).
If it happens that all errors are zero, the average will be done withouth using weights.
Take into account that:
- You cannot play with the options (delete, ignore, bad, uplim, nofit) for 'Calc' points. These are calculated by VOSA. You just can play with the particular observed points that are used to calculate the average value.
- Values marked as 'ignore' won't be used in the average. Thus, if there are three possible values (for instance, one from user input, one from catalogue A and one from catalogue B) and you want to use one of them (so that VOSA does not calculate an average) you only need to mark the other two ones as 'ignore'.
- If any of the points that are used to calculate an average is marked as bad,uplim or nofit, this property is inherited by the average. Let's say that the 'average' point can't be "better" than the "worst" element used for calculating it.
VO photometry information
When available, you will see, for each point coming from a VO catalogue, some information that we have extracted from the catalogue to help you to decide if you want to incorporate it to the final SED or not.
- RA (VO): RA coordinate (degrees) given in the catalogue for this point.
- DEC (VO): DEC coordinate (degrees) given in the catalogue for this point.
- Δ (VO): angular distance from the object position to the position given by the catalogue. If it is large, you could consider the posibility that this entry corresponds to a different object.
- Δ_2 (VO): angular distance from the object position to the position given by the catalogue for the second closest object. If this is small, or similar to Δ (VO) it could mean that the obtained photometry does not correspond to this object but to some counterpart and you should be cautious.
- Nobjs: number of objects found within the search radius (if there are more than 5 the value is shown as 5+). If this value is larger than 1 it could mean that the obtained photometry does not correspond to this object but to some counterpart and you should be cautious.
- OBJName (VO): object name in the VO catalogue.
- Obs.Date (VO): observation date as given in the VO catalogue.
- Qual (VO): quality flag as given by the VO catalogue. When this info is available you will usually be able to click on the flag to access the information about the catalogue and the meaning of each flag.
An example
For instance, in this case (click in the image to enlarge):
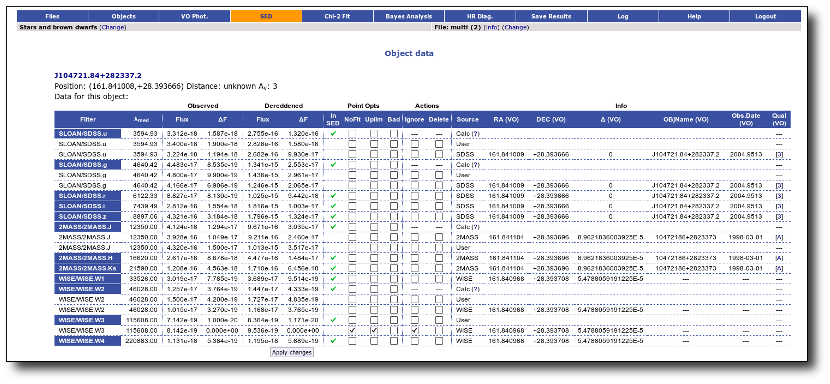
- For SLOAN/SDSS.u, 2MASS/2MASS.J and WISE/WISE.W2 there were two values for each filter, one from user input and one from a VO catalogue. VOSA has calculated an averate and it will be used in the final SED.
- For SLOAN/SDSS.g there are two values too. But, as one of them has been marked as 'nofit', the final average has been automatically marked as 'nofit' too.
- For WISE/WISE.W3 there are two values too. But the one coming from the WISE VO catalogue has been marked as ignore. Thus, this point is ignored and only the user value is there to be considered. VOSA does not need to calculate an average and the user value goes directly to the final SED.
SED download
When you download the final resuls (see ) you will get a file (xml and/or ascii) with the final SED for each object. Most of the information is the same shown in the SED section of VOSA, but with some peculiarities.
When a data point has been calculated as an average of the photometry coming from different services (or user input file) some of the columns in the SED final file are built in terms of the original values for each catalogue. In particular:
- Δ (VO): this is the MAXIMUM value of all the Δ values for the data points combined to build this SED point.
- Δ_2 (VO): this is the MINIMUM value of all the Δ_2 values for the data points combined to build this SED point.
- Nobjs: this is the MAXIMUM value of all the Nobjs values for the data points combined to build this SED point.
- Qual (VO): if, for all the points combined to build this final SED point, the quality flag is the same, that value is shown here. Otherwise it is shown as 'mix'.
| 

 VO photometry
VO photometry